안녕하세요, 하이스트레인저 백엔드 엔지니어 이상훈입니다.
서비스를 운영하다 보면 예상치 못한 서버 이슈를 마주하게 됩니다. 특히 EC2처럼 직접 관리하는 인스턴스는 장애가 발생했을 때 원인 파악부터 복구까지 개발자의 손이 많이 가죠.
이번 글에서는 운영 중인 EC2 서버가 자꾸 죽는 현상을 겪으며 원인을 분석하고, 안정화하기까지의 과정을 공유합니다. 저희 팀이 어떤 방식으로 문제를 추적하고 해결했는지, 그 실전 기록이 비슷한 문제를 겪고 있는 분들께 도움이 되기를 바랍니다.
서버가 처음 죽은 날
2025년 2월 20일 오전 9시경, 저희 씨네랩 서비스의 서버가 약 30분간 다운되는 문제가 발생하였습니다.
당시 서버에 접속하여 원인을 파악하려 했지만, 시스템 자원이 모두 과부하 상태였던 탓인지 접속조차 되지 않는 상황이었습니다. 결국 해당 EC2 인스턴스를 강제로 재부팅한 후에야 원격 접속이 가능했고, 로그를 확인해볼 수 있었습니다.
1 | [ec2-user@ip-10-10-2-89 ~]$ sudo tail -n 6 nohup.out |
가장 최근 로그를 확인해 보니, Thread starvation or clock leap detected 경고 메시지를 통해 시스템 자원 부족으로 인해 장애가 발생했음을 유추할 수 있었습니다.
하지만 이 외에 구체적으로 어떤 쿼리가 문제였는지, 어떤 자원이 병목이었는지에 대한 정보는 전혀 확인할 수 없었습니다. 이는 평소에 충분한 로그 설정이나 시스템 모니터링 환경을 구성해두지 않았기 때문이라는 점을 뼈저리게 느끼게 된 계기였습니다.
이제부터라도 모니터링하자
이번 장애를 겪으며 가장 크게 느낀 점은, 서버의 상태를 사전에 감지하고 대응할 수 있는 체계가 없었다는 것이었습니다. 단순히 EC2 인스턴스를 띄우고 운영만 하고 있었을 뿐, 실제 자원 사용량이나 이상 징후에 대한 모니터링은 거의 이뤄지지 않고 있었습니다.
이런 상황을 개선하고, 같은 문제가 반복되지 않도록 다음과 같은 세 가지 조치를 취했습니다.
CloudWatch 지표 설정
배경: 서버가 다운된 당시, 어떤 자원이 병목이었는지 전혀 확인할 수 없었습니다. 단편적인 nohup.out파일 로그만으로는 부족했습니다.
조치: AWS CloudWatch를 활용하여 CPU, Memory, Disk 사용량을 모니터링할 수 있도록하도록 설정했습니다.
이점: 장애 전후의 리소스 사용 패턴을 명확히 파악할 수 있어, 사전 대응이 가능해졌습니다. 이제는 서버 상태를 매일 눈으로 확인할 수 있는 환경이 갖춰졌습니다.
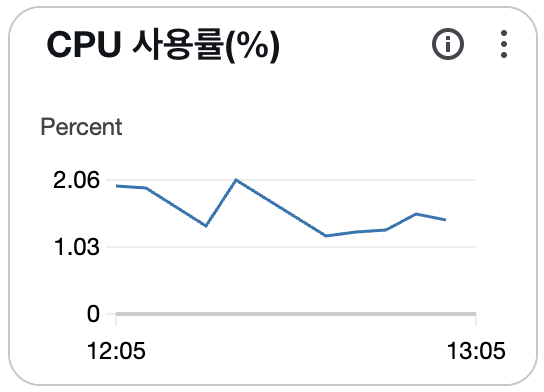
💡 참고: CPU 사용률은 AWS에서 기본 제공되는 CloudWatch 지표로, 별도 설정 없이 바로 확인할 수 있습니다.
반면, Memory와 Disk 사용률은 CloudWatch Agent를 EC2에 설치하고 구성해야 수집 가능합니다.
경보(Alert) 설정
배경: 지표가 있어도 사람이 매번 확인하지 않으면 소용이 없습니다. 리소스가 비정상적으로 증가하는 시점을 자동으로 감지해야 했습니다.
조치: 5분 평균 기준 CPU, Memory, Disk 사용률이 80%를 초과하면, 씨네랩 운영팀의 CS 메일로 경고 알림이 전송되도록 설정했습니다.
이점: 기본적인 모니터링 체계가 구축되어, 문제가 발생하기 전에 대응할 수 있는 기반이 마련되었습니다.
EC2 인스턴스 유형 변경
배경: 현재 문제의 정확한 원인을 특정하지 못한 상태였기에, 어떤 자원이 부족해 또 다시 장애가 발생할지 예측할 수 없었습니다.
조치: EC2 인스턴스를 기존 t3.xlarge (vCPU 4개, 메모리 16GB)에서 t3a.2xlarge (vCPU 8개, 메모리 32GB)로 임시 상향하였습니다.
이점: 인스턴스 사양을 상향한 덕분에 리소스 부족으로 인한 장애 재발 가능성을 줄일 수 있었고, 향후 메모리 누수나 CPU 과사용 같은 병목 현상을 분석하기에도 더 유리한 환경이 마련되었습니다.
다만, 월 EC2 비용이 약 $122.4 증가하는 부담은 감수해야 했습니다.
이 세 가지 조치를 통해 최소한의 모니터링 기반을 갖추게 되었고, 이제는 단순 서버 자원 부족으로 서버가 다운되는 상황은 방지할 수 있게 되었습니다.
메모리가 계속 새고 있었다
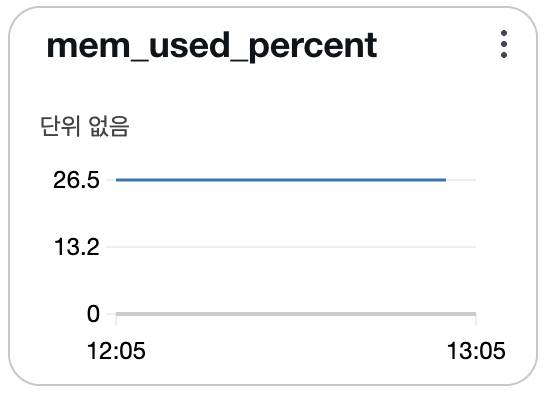
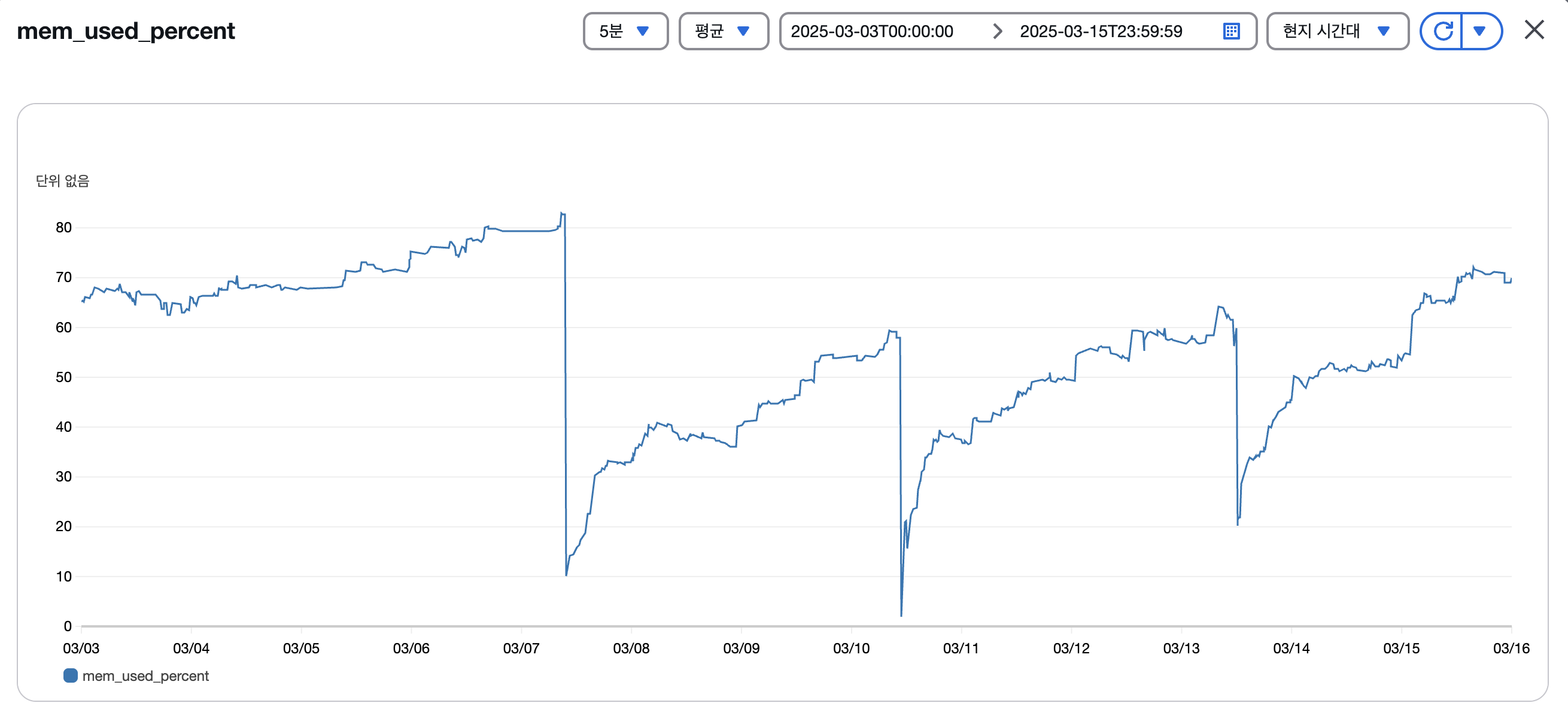
며칠 후, CloudWatch 경보를 통해 씨네랩 EC2 인스턴스의 메모리 사용률이 80%를 초과했다는 알림이 도착했습니다. 확인해보니 메모리 사용량이 시간이 지날수록 점점 증가하고 있었고, 누수가 의심되는 상황이었습니다.
htop으로 확인해보니, MySQL 스레드들이 시스템 메모리의 절반 이상을 차지하고 있었고, 점차 사용량이 늘어나고 있었습니다.
정확한 원인을 파악하기 전까지는 위와같이 MySQL을 수동 재시작하며 임시로 메모리를 관리했습니다.
💡 참고: htop은 리눅스에서 실시간 자원 사용량을 시각적으로 보여주는 도구입니다.
CPU, 메모리, 스레드 등의 정보를 한눈에 볼 수 있어 성능 문제 진단 시 유용합니다.
디테일하게 보자 : 메모리 상세 로깅
MySQL 스레드가 메모리를 과도하게 사용하고 있다는 사실까진 파악했지만, 정확히 어떤 설정이나 상태가 문제인지 알아내기 위해선 더 세밀한 로그가 필요했습니다.
그래서 이를 추적하기 위해, memory_logging.sh 스크립트를 만들어 5분마다 자동 실행되도록 설정했습니다.
1 | # memory_logging.sh ─ 5분마다 서버·MySQL 메모리 상태를 스냅샷으로 남기는 스크립트 |
로그는 memory.log에 누적되며, 아래 세 가지 정보를 수집합니다.
OS 메모리 상태
free -m,/proc/meminfo로 전체·스왑·캐시 사용량 확인ps aux --sort=-%mem으로 메모리를 가장 많이 쓰는 상위 20개 프로세스 기록어떤 프로세스가 얼마나 메모리를 사용하는지 추적할 수 있습니다.
커널 및 시스템 로그
dmesg,/var/log/messages에서 최근 커널 경고와 시스템 이벤트 확인OOM Kill, 프로세스 재시작 등 이상 징후를 감지합니다.
MySQL 메모리 상태
SHOW ENGINE INNODB STATUS\G
→ 현재 트랜잭션, 잠금 상태, 버퍼 풀 사용 현황 등을 확인할 수 있습니다.SHOW GLOBAL VARIABLES
→ 버퍼, 조인, 정렬 등에 할당된 메모리 설정값을 확인합니다.SHOW GLOBAL STATUS
→ 실행 중인 스레드 수, 임시 테이블 생성 횟수 등 실제 사용량을 확인합니다.이 세 가지를 함께 보면, MySQL의 메모리 설정값과 실제 사용량 차이를 파악할 수 있습니다.
문제의 원인은 바로 이것이었다
며칠간의 로깅 이후, memory.log 파일을 살펴보니 MySQL의 활성 스레드 수가 줄어들지 않는 현상이 계속되고 있었습니다.
당시 서버는 Spring Boot 기반으로 운영되고 있었고, 데이터베이스 커넥션 풀은 HikariCP를 사용하고 있었는데요. 무언가 설정에 문제가 있는 것 같아 application.properties 파일을 확인해 보니, Hikari 관련 설정이 전부 주석 처리된 상태였습니다.
이에 아래와 같이 커넥션 풀 관련 설정을 새로 추가하였습니다.
1 | # --- HikariCP 커넥션 풀 설정 --- |
설정 적용 이후, CloudWatch 메모리 지표를 통해 시스템의 메모리 사용량이 안정적으로 유지되는 것을 확인할 수 있었습니다.
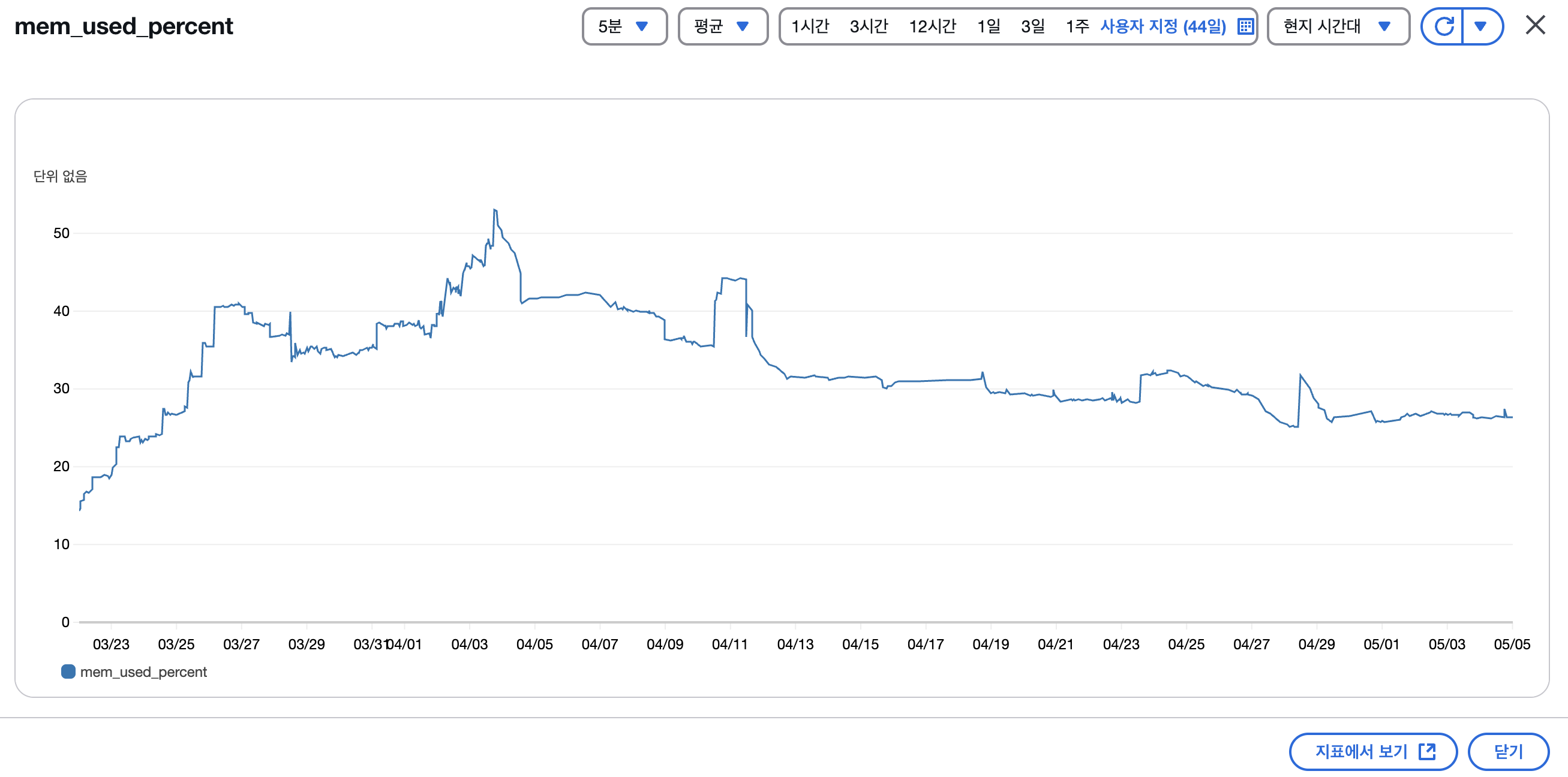
💡 참고: HikariCP는 Spring Boot의 기본 커넥션 풀 라이브러리로, 빠른 속도와 안정성으로 널리 사용됩니다.
커넥션을 재활용해 DB 연결 비용을 줄이고, 커넥션 누수도 방지할 수 있습니다.
마치며: 서버 장애가 남긴 두 가지 교훈
운영 단계의 시스템은 예외 없이 Observability(가시성)을 갖춰야 하고, 그 핵심이 바로 모니터링과 로깅입니다.
1. 모니터링 ― ‘지금’ 무슨 일이 일어나고 있는지 알려준다
- 미리 알림 : CPU나 메모리 같은 사용량을 실시간으로 지켜보면, 장애가 발생하기 전에 이상 징후를 포착할 수 있습니다.
- 한눈에 보기 : 대시보드와 알림 덕분에 서버 상태를 직관적으로 파악하고 문제 지점을 빠르게 찾을 수 있습니다.
2. 로깅 ― ‘왜’ 그런 일이 일어났는지 기록한다
- 원인 찾기 : 상세 로그가 있으면 문제를 재현하지 않고도 원인을 파악할 수 있습니다.
- 재발 방지 : 에러나 이상 활동을 기록해 두면, 똑같은 문제가 재발하는 것을 막을 수 있습니다.
- 빠른 대응 : 장기 로그를 통해 서버의 사용 패턴을 파악하고, 필요한 경우 사전 대응(업그레이드, 튜닝 등)이 가능합니다.
이번 경험을 통해, 서버가 죽은 뒤에야 원인을 찾기 시작하는 수동적 운영 방식에서 벗어나 모니터링·로깅 기반의 운영 방식으로 한걸음 나아갈 수 있었습니다.
이 기록이 비슷한 문제로 고민 중인 여러분께 작은 힌트가 되길 바랍니다.
읽어주셔서 감사합니다.
참고 문서
AWS CloudWatch Agent를 통한 메모리 지표 설정
Amazon Web Services, Inc.Spring Boot에서 HikariCP 설정하기
BaeldungMySQL 메모리 사용량 모니터링
MySQL 개발자 존